One of the questions I ask first when I give talks to prospective students or public groups is “What is Software Engineering?”, and then get their responses. Usually the answers are similar; “programming”, “building an app”, “writing code” – all along the technical development line.
My next step (not that it does much for student numbers) is to tell them they’re wrong, that people focus on the programming and development aspects but in fact software engineering is not just programming in the same way that bridge building is not just bricklaying. If you were to say someone was a “Bridge Engineer” it could be they did everything from designing, testing, model making, laying foundations, sinking piles, suspending cables, or, yes indeed, bricklaying. In fact I say, no doubt smugly and patronisingly, “Software Engineering isn’t a job or a profession, it’s a whole industry”. The next 20 minutes or so are then filled as I labour the point and talk about the roles from requirements engineering through programmer to systems engineer, before they troop dejectedly out for a free lunch.
But this got me thinking; what if we did build bridges in the same way we build software?
Certainly there’s no doubt software engineering has advanced leaps and bounds since the Software Crisis of the 60’s, and a great deal has changed since Fred Brooks’ famously categorised software projects as “werewolves” (monsters that can turn around at any time and bite you!). But, advances aside, software projects can and do still fail, and the world is full of semi-functional legacy systems nobody dares to touch for fear of the house of cards collapsing.
Sure, in the formalised world of big business and large projects, generally we now expect projects to succeed. Good requirements engineering (knowing what you should actually be building!), software design (a sensible design to meet the goals and evolve), iterative development and agile approaches (building it a piece at a time, checking in with the customer on a regular basis, responding to change), testing (making sure it actually works!), and use of fancy modern cloud infrastructure (making it someone else’s responsibility to keep the lights on) has made this happen. But is this how most software is developed? As we’ve democratised software development, made a million open access resources and put a computer in every pocket, we are now in a position where most coding is being done in bedrooms or in small offices by individuals or tiny teams. Is this all being done in adherence with best practice on requirements traceability and agile principles? Probably not.
Are even we as professional software engineers eating our own dog food? How many utility scripts or programs in our home directories could be referred to as “quick dirty hacks”?
So, what if we built bridges the same way we (a lot of the time) build software?
We’d start with a seemingly simple requirement – I need to cross a river.

A simple solution then – drop some big rocks in which can act as stepping stones.
Brilliant! This solves the immediate problem and our gallant hero can cross to market and buy some bronze, or a chicken, or something.
However in the cauldron of innovation that is humanity someone goes and invents the wheel, and creates a cart. After trying to attach it to the aforementioned chicken, an unimpressed pig, and some crows, someone tries a horse and the winning formula is found. Except horses and wheels can’t use stepping stones (the requirements have evolved).
Simple answer – lay some planks over the stones.

Time passes, the wheel is voted “best thing prior to sliced bread” four years in a row, and horses and carts cross our bridge back and forth. But there’s no stopping progress, and some lunatic builds a steam-powered cart on rails known as a train, much to the anger of the horses’ union. The train is much heavier than the cart, can’t go up and down banks, and needs rails so we modify the bridge again. We raise the deck, lay the rails, building on top of the planks resting on the stepping stones.
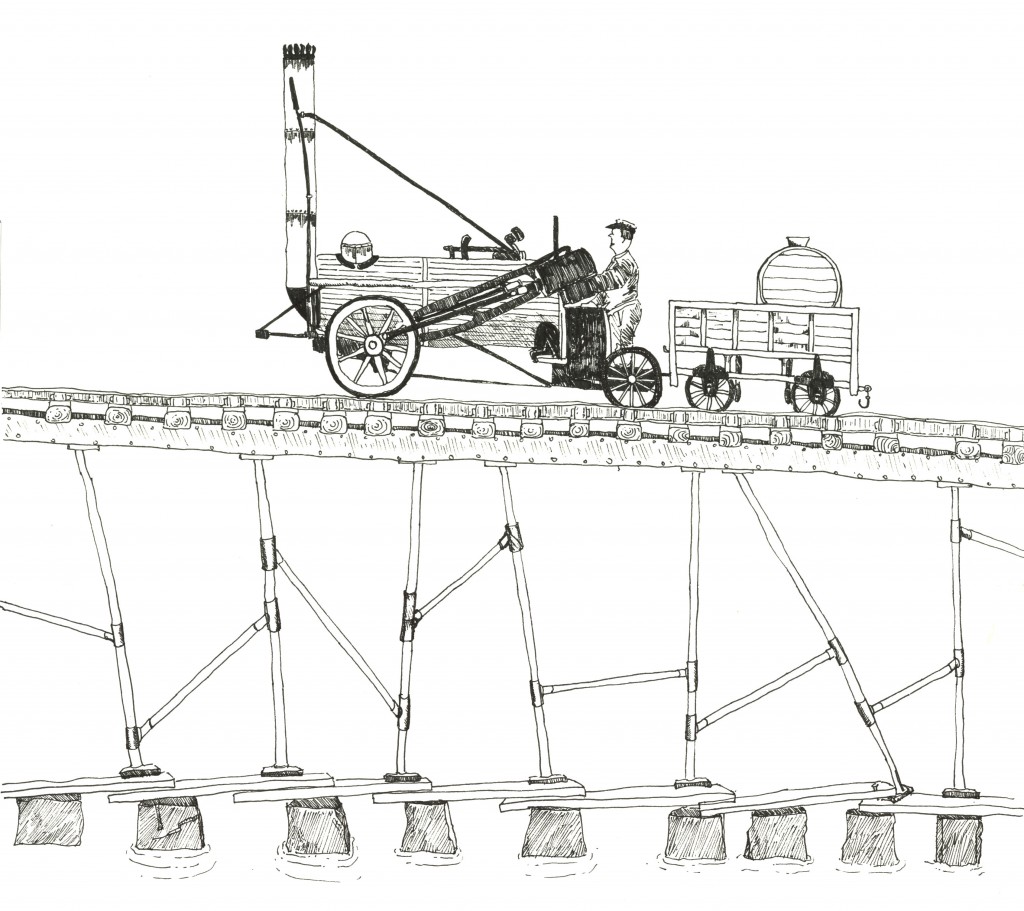
Trains, it turns out, are way more popular than horse-drawn carts, and make much better settings for murder mysteries. As their number and use increases they get heavier and heavier, faster and faster. No longer will the rickety beams hold up so the bridge is reinforced over and over, as each new train comes onto the line.
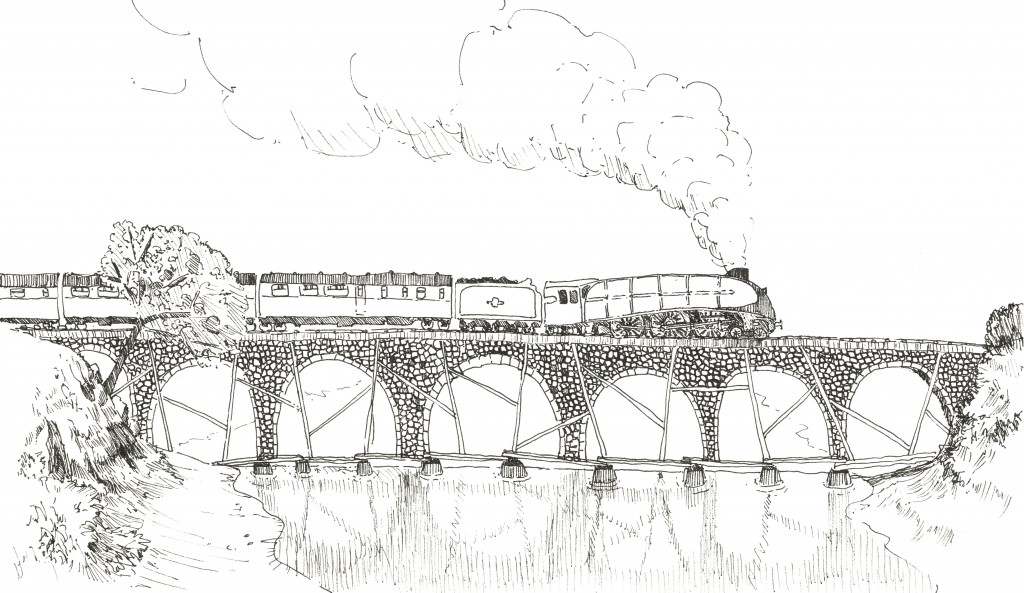
In time even steam becomes passé, some joker goes and puts the new-fangled internal combustion engine in it’s own little chariot and the age of the motor-vehicle is born.
Quick as a flash the bridge solution is found, and a new suspended roadway is bolted on the top!
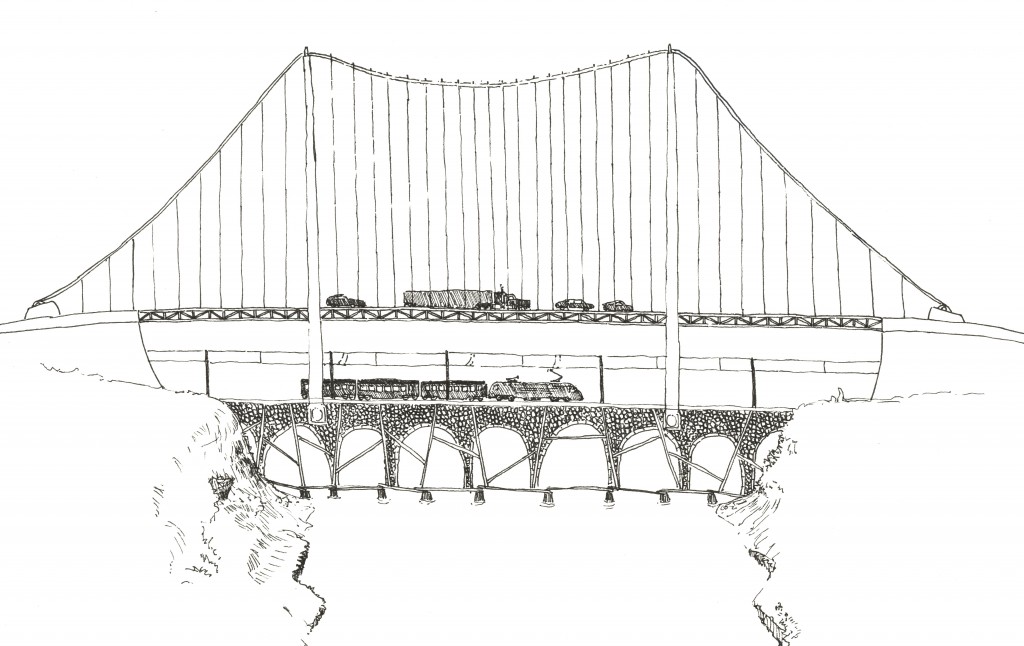
Evolved from stepping stones, still standing on those very foundations, and being used heavily day in, day out. It works, mostly, taking more volume and type of traffic than ever before, outliving by far the stepping stone engineer and many afterwards who cared for and modified it through the centuries.
Here we are, bang up to date, with a legacy bridge that has evolved over the years and with the majority of the engineers dead and gone, some from the black death.
Now Dave is responsible for maintaining the bridge, the hodge-podge of obsolete half-forgotten technologies, built by people long since gone using techniques long since lost to the sands of time.
One day, carrying about his usual bridge duties, he sees a cable he thinks is loose…
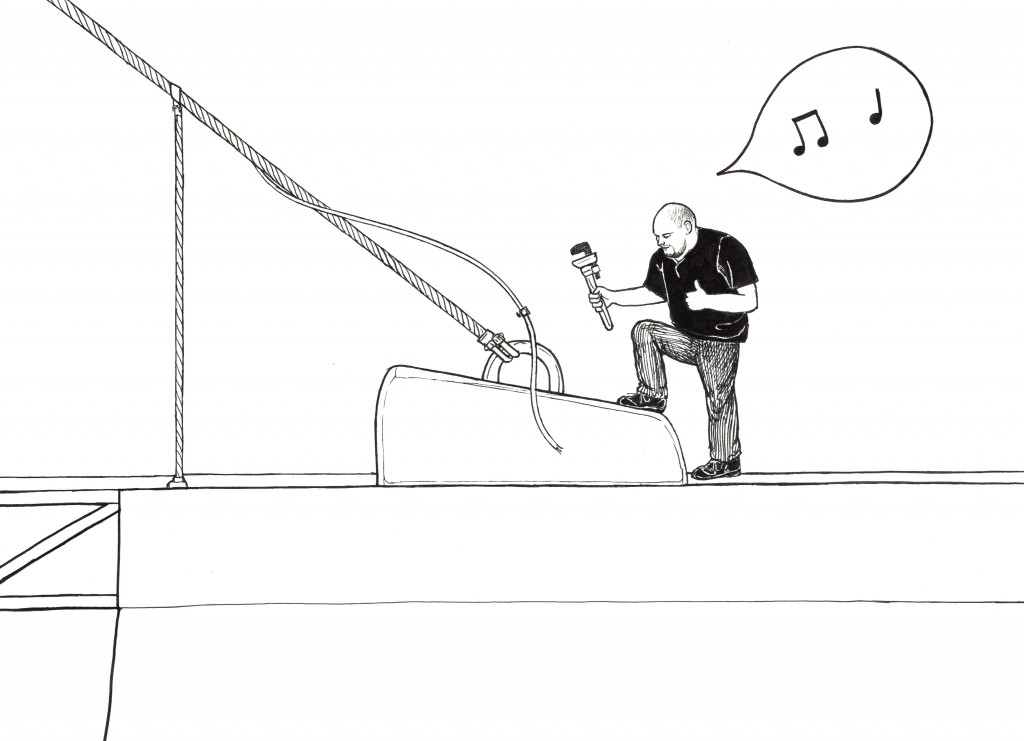
And being a conscientious sort he gives it a good old tighten up.
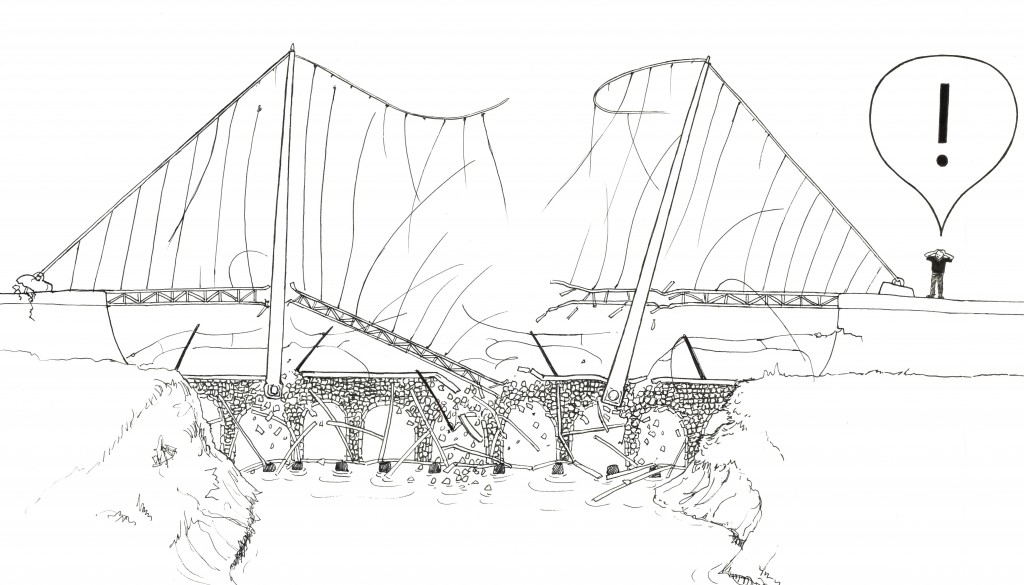
So the bridge collapses, spectacularly, probably just as a busload of orphans and accompanying nuns are travelling across. There is outcry, rage, incomprehensible gibberish of outrage on twitter, fingers pointed at the government, promises of enquiries, and a desire on all sides to find someone to blame. The burden of blame naturally falls on the obvious suspect, the man with the smoking wrench in hand, Dave.

We know who to blame, and everyone can rest assured it was definitely, and uniquely, his fault. He rots in jail, flowers are laid at the old bridge site, and we start all over again.
But is this really how software is developed?
I believe so, yes. Certainly more often than it should, and more often than we would like to admit. All too often software is quickly (and dirtily!) built to solve the minimum problem right now, and even at the time we say things like “when I get time I’ll come back and do this properly” or “well this will do for now until we replace it/the need goes away”, and how often do we do that? We could just as well say “well this will do until pigs fly to the moon and prove it’s made of cheese”.
But the initial quick dirty solution isn’t the problem. The issue comes with uncontrolled evolution. As much as night follows day (follows night, follows day, etc) requirements will change, we in the IT industry exist in a state of constant flux, nothing stands still for long. By it’s very nature successful software and successful systems will be required to face change and evolve to meet new requirements continually. When we “hack” these requirements onto our, only intended for short term use, original “quick and dirty” solution, we rapidly introduce all sorts of unintended complexity and integration issues – we make ourselves a codethulu or screaming tower of exceptions.
Yet we still rarely learn our lesson because once we’ve hacked one new set of requirements in and it works, sort of, in a “don’t press G on the third input field or it’ll crash” kinda way we stride away feeling like code-warrior bosses and not looking back. Until the next inevitable change.
So Brooks is still right?
Well obviously – the man is a genius after all. The essential difficulties he identified with software are still present in most cases.
- Complex – Check! More complex than ever really. As computer power grows so does our demand on what we can do with it. Of course if we properly decompose a problem down we can reduce the complexity, but that’s doing things properly.
- Subject to external conformity – yes siree! External stuff is changing all the time and it’s expected that the software can be tweaked to conform; we don’t change the printer spec to make it work with the software, we change the software.
- Changeable – more than ever! Change is a natural part of software and entirely unavoidable, unless you’re MySpace.
- Invisible – Unlike bridges we can’t see software, we can’t kick it, or go and marvel at it’s grandeur, prod a few bits to understand it’s function. Yes now we have UML and various design tools but only if we do things properly which, often, we don’t.
But most of the time even unplanned development projects deliver, so haven’t things got better?
Ah yes, what I like to call the “fallacy of the initial success” (catchy name, right?). If I set out to build a software system to do X and I stick at it, I normally expect the system will eventually do X. The project probably won’t fail partway through into a pit of recrimination and blame.
This is because we now have some amazing tools at our disposal. Web scripting languages combined with HTML and a browser mean anyone can build a program with a UI. Memory managed (garbage collected) languages mean who cares about freeing resources, or causing hardware resets by accessing the wrong address in RAM. Stack overflow will answer most queries for us, and the world is full of talented developers who put their libraries and source free and available online for us to use. So to sit down and build something to do X, no problem! Everything is rosy and it’s home for tea and medals!
The problem however is Y and Z, new requirements that follow on with apparent inevitability. I’ve been in the business long enough to know when I say to myself “it’ll only need to do X” that I am blatantly lying to myself.
My hypothesis then is that: rather than solving the problem with software development, we’ve mainly just transferred the risk from the front-end (initial development) to the back-end (maintenance and modification) of the development lifecycle.
It’s true we may no longer have werewolves in every project, ready to turn into beasts and sink their teeth into us – the stuff of nightmares, but we certainly now have our fair share of zombies. Many of these are the relatively benign shuffling-gait “braaaaaains…” type, easily avoided or picked off at our leisure, but there’s also a large number of buttock-clinchingly scary 28-days style vicious running zombies. These are the myriad of legacy programs we’re surrounded by, just waiting for the opportunity to smash their way out of the coffin and chase us down for breakfast brains.
So what’s the solution?
All the above is based on one premise – that the lovely and excellent principles of proper software engineering from requirements gathering, analysis, design (flexible, extensible, reusable, standardised, highly cohesive and lowly coupled), agile development, prototyping, stakeholder engagement, iterative methods aren’t being followed (which sadly I think happens most of the time – of course if you are following good practice then of course nothing can go wrong [ha!], or at least we hope not this particular mess).
So the simple solution is to follow good practice. To try and take a little more time in the design and implementation of solutions, consider the future maintainability and reuse potential; build software to last years not days or months. Listen to the little bit of us that screams with impotent rage when we “just quickly bodge this”.
We also shouldn’t ever be afraid to tear it down and start again. Iterative does not always mean incremental, if something is becoming unfit for purpose can’t we find the time to invest in sorting it properly? How much time do we really spend on preventative maintenance compared to how much we should? Is it fire-fighting or careful fireproofing to avoid the emergency?
If you want to fix the roof, better do it while the sun is shining.
There are attempts at automated approaches to help us manage these zombie programs, and in fact a large part of my research is on this kind of area. But don’t worry, if we all start coding properly – engineering not just programming – tomorrow, there’s still plenty of zombies out there already created, so you’re not doing me out of a job. My confrontational attitude and willingness to tell prospective students they’re wrong when I ask them a trick question will do that for me.
Good documentation is another good idea (assuming you’re not following a good practice that tells you documentation is the very spawn of Satan) but remember; documentation can end up evolving like code, we end up with too much of it telling us too little and unsure where to find the little nugget of information we need amongst the volumes. Dave (the bridge man) had plenty of blueprints, and if he understood them all he would have known not to tighten the fateful wire, but how was he to know?

David Cutting is a senior research associate at the Tyndall Centre at UEA, associate tutor, partner at Verrotech, CTO of tech startup Gangoolie, and alleged software engineer (purveyor of much shoddy half-built freeware) – he does not eat his own dog food often enough. He holds both a PhD and an MSc in computer science and by that gives even the poorest student hope. This article is a cut-down version of a presentation entitled “Software! It’s Broken” he gives when anyone will listen. Artwork by Justin Harris and Amy Hunter.
All content is (C) Copyright 2015-2017 David Cutting (dcutting@purplepixie.org), all rights reserved.